# PythonによるWebサイトの自動検索-1
# いくつかのニュースサイトから特定の語句をキーワードに検索し、メディア名、掲載日時、ニュースタイトル、ニュースURLをExcelに保存する
# 必要なモジュールを呼び出す
import requests
from bs4 import BeautifulSoup
from datetime import datetime, date, time , timedelta
import re
import os
import pandas as pd
from openpyxl import load_workbook
# 検索結果からメディア、タイトル、URL、掲載日時を抽出したときに格納するリスト
r_media = []
r_title = []
r_url = []
r_date = []
# 検索キーワードを指定する
key0 = '清水建設'
key1 = key0 # 読売新聞、Yahoo!、建設工業新聞用のキーワード
key2 = key0 + ' NOT 逆日歩' # 日経新聞用のキーワード
# 検索期間を指定する
ni = 30 # 本日から何日前まで検索するかを指定して「ni」に格納する
# 検索結果を出力するディレクトリ「dir」を指定する
dir = r'C:\Users\......\......\......\......\......'
# 検索に利用する様々な日付を作成する
now = datetime.now() # 現在の日時
nt = date(now.year,now.month,now.day) # 現在の年月日
ny = str(nt.year) # 現在の年
nm = str(nt.month) # 現在の月
nmz = nm.zfill(2) # 現在の月が1桁の場合は前ゼロを付けて2桁に揃える
nd = str(nt.day) # 現在の日
ndz = nd.zfill(2) # 現在の日が1桁の場合は前ゼロを付けて2桁に揃える
ft = nt - timedelta(days=1)*ni # ni日前の年月日
fy = str(ft.year) # ni日前の年
fm = str(ft.month) # ni日前の月
fmz = fm.zfill(2) # ni日前の月が1桁の場合は前ゼロを付けて2桁に揃える
fd = str(ft.day) # ni日前の日
fdz = fd.zfill(2) # ni日前の日が1桁の場合は前ゼロを付けて2桁に揃える
# 読売新聞(YOMIURI ONLINE) サイト内検索--------------------------------------------------
# ニュース検索サイトのメディアとURLを指定する
media = '読売新聞'
url = 'https://www.yomiuri.co.jp/web-search'
# 検索キーワードを指定して「key」に格納する
key = key1
# 検索パラメータを設定する(キーワード、検索期間)
params = {'st':'1','wo':key,'ac':'srch','ar':'1','fy':fy,'fm':fm,'fd':fd,'ty':ny,'tm':nm,'td':nd}
# URLとパラメータを設定して検索リクエストを送り、検索結果を「r」に格納する
r = requests.get(url, params=params)
r.raise_for_status()
# 検索結果をBeautifulSoupで分析して「soup」に格納する
soup = BeautifulSoup(r.content,'html.parser')
# 「soup」から検索したニュースのタイトルとURLが入っている「class」の内容を「r_titles」 に、ニュースの件数を「n」に格納する
r_titles = soup.find_all(class_='c-list-title c-list-title--default')
n = len(r_titles)
# 「soup」からニュースの掲載日時が入っている「class」の内容を「r_dates」 に格納する
r_dates = soup.find_all(class_='c-list-date')
# 各ニュースのメディア名「r_media」、タイトル名「r_title」、URL「r_url」、掲載日時「r_date」を抽出してリスト化する
for i in range(n):
r_media += [media] # メディア名
r_title += [r_titles[i].text.replace('\n','').replace(' ','')] # タイトル名(改行記号やスペースは除去)
r_url += [r_titles[i].find('a').get('href')] # URL(タグ名「a」と属性名「href」で取得)
r_date += [r_dates[i].text.replace('\n','').replace(' ','')] # 掲載日時(改行記号やスペースは除去)
# 掲載日時の書式を yyyy/mm/dd HH:MM 形式に整える
if r_date[i][0:3] != '202':
r_date[i] = ny+'/'+nm+'/'+nd+r_date[i] # 本日の記事は時分しか出ないので年月日を加える
r_date[i] = datetime.strptime(r_date[i],'%Y/%m/%d%H:%M').strftime('%Y/%m/%d %H:%M')
n1 = n
# 日経新聞(日経電子版) サイト内検索--------------------------------------------------
# ニュース検索サイトのメディアとURLを指定する
media = '日経新聞'
url = 'https://www.nikkei.com/search?'
# 検索キーワードを指定して「key」に格納する
key = key2
# 検索パラメータを設定する(検索期間、キーワード、volume(仮に 100 としておく))
params = {'keyword':'to:'+ny+'/'+nmz+'/'+ndz+' '+'from:'+fy+'/'+fmz+'/'+fdz+' '+key,'volume':100}
# URLとパラメータを設定して検索リクエストを送り、検索結果を「r」に格納する
r = requests.get(url, params=params)
r.raise_for_status()
# 検索結果をBeautifulSoupで分析して「soup」に格納する
soup = BeautifulSoup(r.content,'html.parser')
# 「soup」から検索したニュースのタイトルとURLが入っている「class」の内容を「r_titles」 に、ニュースの件数を「n」に格納する
r_titles = soup.find_all(class_='nui-card__title')
n = len(r_titles)
# 「soup」からニュースの掲載日時が入っている「class」の内容を「r_dates」 に格納する
r_dates = soup.find_all(class_='nui-card__meta-pubdate')
# 各ニュースのメディア名「r_media」、タイトル名「r_title」、URL「r_url」、掲載日時「r_date」を抽出してリスト化する
for i in range(n):
r_media += [media] # メディア名
r_title += [r_titles[i].find('a').get('title')] # タイトル名(タグ名「a」と属性名「title」で取得)
r_url += [url.replace('search?','')+r_titles[i].find('a').get('href')] # ★URL(日経サイトのドメインに、タグ名「a」と属性名「href」で取得したディレクトリを付加)
r_date += [r_dates[i].text.replace('\n','').replace(' ','').replace('付','')] # 掲載日時(改行記号やスペースや「付」は除去)
# 掲載日時の書式を yyyy/mm/dd HH:MM 形式に整える(時間表示がないものは yyyy/mm/dd 形式)
if r_date[i+n1].find('時') != -1:
dt = str(datetime.strptime(r_date[i+n1],'%Y年%m月%d日%H時%M分').strftime('%Y/%m/%d %H:%M'))
else:
dt = str(datetime.strptime(r_date[i+n1],'%Y年%m月%d日').strftime('%Y/%m/%d'))
r_date[i+n1] = dt
n1 += n
# Yahoo!ニュース サイト内検索--------------------------------------------------
# ニュース検索サイトのメディアとURLを指定する
media = 'Yahoo!'
url = 'https://news.yahoo.co.jp/search?'
# 検索キーワードを指定して「key」に格納する
key = key1
# 検索パラメータを設定する(キーワード、カテゴリ(仮に国内・国際・経済・IT・科学に絞り込み))
params = {'p':key,'ei':'utf-8','categories':'domestic,world,business,it,science'}
# URLとパラメータを設定して検索リクエストを送り、検索結果を「r」に格納する
r = requests.get(url, params=params)
r.raise_for_status()
# 検索結果をBeautifulSoupで分析して「soup」に格納する
soup = BeautifulSoup(r.content,'html.parser')
# 「soup」から検索したニュースのタイトルが入っている「class」の内容を「r_titles」 に、ニュースの件数を「n」に格納する
r_titles = soup.find_all(class_='newsFeed_item_title')
n = len(r_titles)
# 「soup」から検索したニュースの元メディア名が入っている「class」の内容を「r_medias」 に格納する
r_medias = soup.find_all(class_='newsFeed_item_media')
# 「soup」から検索したニュースのURLが入っている「class」の内容を「r_urls」 に(Yahoo!は2種類あるので2つとも)格納する
r_urls = soup.find_all(class_=[
'viewableWrap newsFeed_item newsFeed_item-normal newsFeed_item-ranking',
'viewableWrap newsFeed_item newsFeed_item-normal newsFeed_item-ranking newsFeed_item-movie'
])
# 「soup」からニュースの掲載日時が入っている「class」の内容を「r_dates」 に格納する
r_dates = soup.find_all(class_='newsFeed_item_date')
# 各ニュースのメディア名「r_media」、タイトル名「r_title」、URL「r_url」、掲載日時「r_date」を抽出してリスト化する
for i in range(n):
r_media += [media + '(' + r_medias[i].text + ')'] # メディア名(元メディア名)
r_title += [r_titles[i].text.replace('\n','').replace(' ','')] # タイトル名(改行記号やスペースは除去)
r_url += [r_urls[i].find('a').get('href')] # URL(タグ名「a」と属性名「href」で取得)
r_date += [re.sub('月|火|水|木|金|土|日','',r_dates[i].text).replace('(','').replace(')','')] # 掲載日時(カッコ付曜日を除去)
if r_date[i+n1][0:3] != '202':
r_date[i+n1] = ny + '/' + r_date[i+n1] # 掲載日時(年表示が省略されていれば現在年を付ける)
# 掲載日時の書式を yyyy/mm/dd HH:MM 形式に整える
r_date[i+n1] = datetime.strptime(r_date[i+n1],'%Y/%m/%d %H:%M').strftime('%Y/%m/%d %H:%M')
# 掲載日時が ni日前の年月日を超えた場合は中断する(Yahoo!では検索期間設定ができないため)
nd_time = datetime.strptime(r_date[i+n1],'%Y/%m/%d %H:%M')
nd = date(nd_time.year,nd_time.month,nd_time.day)
if nd < ft:
del r_media[i+n1],r_title[i+n1],r_url[i+n1],r_date[i+n1] # ni日前の年月日を超えている最後の1件を削除
i = i - 1
break
n1 += i + 1 # 検索総件数「n」ではなくbreak時の件数「i」を使用
# 建設工業新聞 サイト内検索--------------------------------------------------
# ニュース検索サイトのメディアとURLを指定する
media = '建設工業新聞'
url = 'https://www.decn.co.jp/?'
# 検索キーワードを指定して「key」に格納する、またページ番号を 1 とし「p」に格納する
key = key1
p = 1
# 1ページ10件までしか検索表示されないので、掲載日時が ni日前の年月日を超えるまでページ数を増やして検索を繰り返す
flag = '0'
while flag != '1':
# 検索パラメータを設定する(キーワード、ページ)
params = {'s':key,'paged':p}
# URLとパラメータを設定して検索リクエストを送り、検索結果を「r」に格納する
r = requests.get(url, params=params)
r.raise_for_status()
# 検索結果をBeautifulSoupで分析して「soup」に格納する
soup = BeautifulSoup(r.content,'html.parser')
# 「soup」から検索したニュースのタイトルとURLが入っている「class」の内容を「r_titles」 に、ニュースの件数を「n」に格納する
r_titles = soup.find_all(class_='Title')
n = len(r_titles)
# 「soup」からニュースの掲載日時が入っている「class」の内容を「r_dates」 に格納する
r_dates = soup.find_all(class_='date')
# 各ニュースのメディア名「r_media」、タイトル名「r_title」、URL「r_url」、掲載日時「r_date」を抽出してリスト化する
for i in range(n):
r_media += [media] # メディア名
r_title += [r_titles[i].text.replace('\n','').replace(' ','')] # タイトル名(改行記号やスペースは除去)
r_url += [r_titles[i].find('a').get('href')] # URL(タグ名「a」と属性名「href」で取得)
r_date += [r_dates[i].text.split(' ')[0].replace(' ','')] # 掲載日時([~面]やスペースは除去)
# 掲載日時の書式を yyyy/mm/dd 形式に整える
r_date[i+n1] = datetime.strptime(r_date[i+n1],'%Y年%m月%d日').strftime('%Y/%m/%d')
# 掲載日時が ni日前の年月日を超えた場合は中断する(建設工業新聞では検索期間設定ができないため)
nd_time = datetime.strptime(r_date[i+n1],'%Y/%m/%d')
nd = date(nd_time.year,nd_time.month,nd_time.day)
if nd < ft:
del r_media[i+n1],r_title[i+n1],r_url[i+n1],r_date[i+n1] # ni日前の年月日を超えている最後の1件を削除
flag = '1'
i = i - 1
break
p += 1 # ページ番号を増やす
n1 += i + 1 # 検索総件数「n」ではなくbreak時の件数「i」を使用
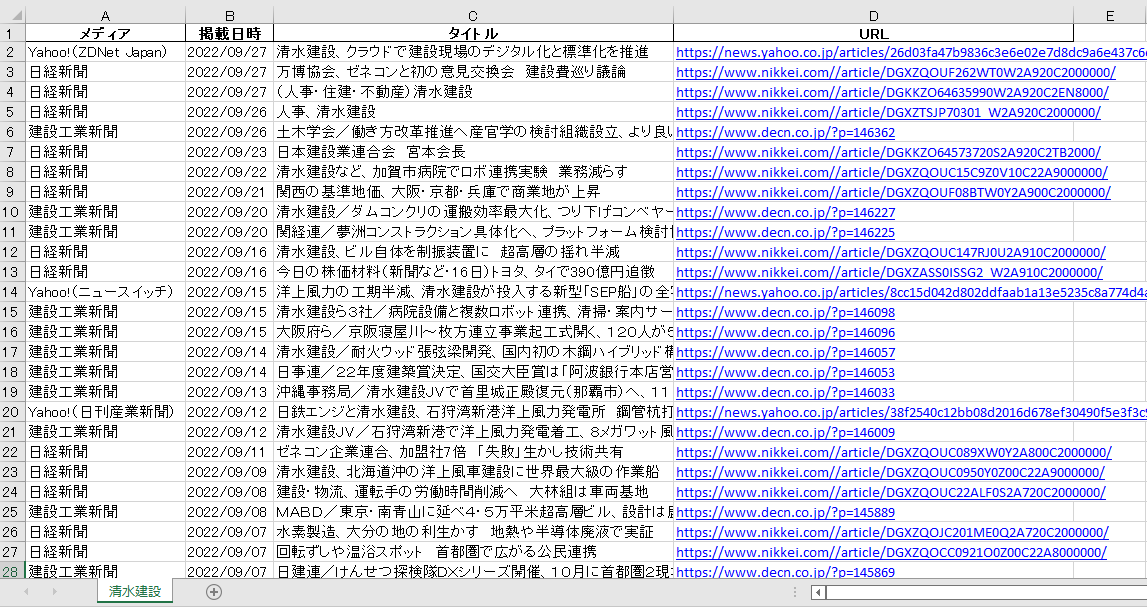
# 検索結果を画面に出力する(メディア順)--------------------------------------------------
print('検索期間:from '+str(ft)+' ~ to '+str(nt))
for i in range(n1):
print(i+1)
print(r_media[i])
print(r_date[i])
print(r_title[i])
print(r_url[i])
# 検索結果をExcelファイルに出力する(掲載日降順)--------------------------------------------------
# 検索結果を「list」に出力する
list = []
for i in range(n1):
list.append([r_media[i],r_date[i],r_title[i],r_url[i]])
# 「list」をデータフレーム「df」に格納し、掲載日時の降順にソートする
df = pd.DataFrame(list, columns=['メディア','掲載日時','タイトル','URL'])
df = df.sort_values(by='掲載日時',ascending=False)
# 「df」をExcelに出力する
nam = 'ニュース検索('+key0+')'+ny+nmz+ndz+'~'+str(ni)+'日前.xlsx'
path = os.path.join(dir,nam)
df.to_excel(path,sheet_name=key0,index=False)
# Excelシートの列幅を修正する ★for~文に変更
col = [['A',20],['B',11],['C',50],['D',50]] # 列番号(アルファベット)と列幅の組合せをリスト化
wb = load_workbook(path)
ws = wb.active
for i in range(len(col)):
ws.column_dimensions[col[i][0]].width = col[i][1]
wb.save(path)